
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 아나콘다 #맥 #anaconda #mac #zsh
- 빅데이터 #인공지능 #머신러닝 #딥러닝 #데이터사이언티스트
- 빅러닝 #파이썬 #아나콘다 #Aanaconda #개발환경 #판다스 #맷플롯립 # 시본 #넘파이 #사이파이 #심파이 #머신러닝 #딥러닝 #스태츠모델 #지오판다스 #텍스트분석 #Sonlp
- Today
- Total
newbom
01장. 빅데이터와 인공지능 본문
1. 빅데이터와 인공지능 그리고 머신러닝
도로를 달리는 컴퓨터
자율주행차량은 주변 환경을 실시간으로 파악하고 차량 스스로 결정을 내려 운행이 가능한 컴퓨터가 되고 있다.
오늘날 평균적인 보통 사람들은 하루에 약 1.5GB 인터넷을 사용한다.
반면 자율주행차량 한 대는 2,666명의 인터넷 사용자와 비슷한 데이터를 단 하루 만에 만들어낸다.
수백 가지의 센서를 통해 아주 많은 데이터를 생산하는 도로 위 컴퓨터인 자율주행차량은 앞으로 상상 이상으로 생산될 것으로 예상한다.
| 구분 | 0단계 | 1단계 | 2단계 | 3단계 | 4단계 | 5단계 |
| 명칭 | 수동 | 운전자 보조 | 일부 자동화 | 조건부 자동화 | 높은 자동화 | 완전 자동화 |
| 운전자 개입 | 항상 | 항상 | 항상 | 요청 시 | 특정 상황 | 없음 |
| 기술 | 없음 | ADAS* | ADAS | ADS* | ADS | ADS |
| 회사 | 테슬라 | 우버 | 웨이모 |
*ADAS(Advanced Driver Assistance System)
*ADS(Automated Driver System)
컴퓨팅 파워
중앙처리장치(CPU: Central Processing Unit)의 발전으로 노트북에서도 작은 딥러닝 모델을 실행시킬 수 있다.
하지만 컴퓨터 비전이나 음성 인식에서 사용되는 일반적인 딥러닝 모델들은 노트북에 비해 10배 이상의 계산 능력이 필요하다.
2000년대에 그래픽 전문 회사들은 비디오 게임의 그래픽 성능을 높이기 위해 대용량 고속 병렬 칩인 그래픽처리장치(GPU: Graphics Processing Unit)을 발전시켰다.
이러한 칩은 저렴한 슈퍼 컴퓨터와 같은 역할을 하므로 CPU가 소량의 GPU로 대체되고 있다.
이후, 딥러닝의 효율을 높이기 위해 특화된 딥러닝 칩에 투자하기 시작했고 그 대표적인 예가 구글의 텐서 처리장치(TPU: Tensor Processing) 프로젝트로 기존 GPU보다 10배 이상 빠른 속도와 효율적인 에너지 소비로 또 다른 머신러닝 하드웨어 발전을 선도하고 있다.
빅데이터와 인공지능의 발전
| 구분 | 1세대 | 2세대 | 3세대 | 4세대 |
| 기술 | OLTP | OLAP/DW | 빅데이터 | AI |
| 연도 | ~1999 | 2000 | 2007 | 2016~ |
| 대상 | 정형 | 정형(다차원) | 정형-비정형 | 지능화 데이터 |
1세대
비즈니스 업무 처리를 지원하는 온라인거래처리시스템(OLTP: On-Line Transaction Processing)이 발전했으며 OLTP는 컴퓨터를 통해 데이터베이스를 갱신하거나 조회하는 등의 단위 작업[트랜잭션(Transaction)]을 의미한다.
2세대
OLTP에서 비지니스 트랜잭션을 통해 생성된 데이터들은 대용량 데이터를 고속으로 처리하며 쉽고 다양한 관점에서 추출, 분석할 수 있도록 지원하는 데이터 분석 기술(OLAP: On-Line Analyrical Processing)이 발전했다.
데이터를 다양항 패턴으로 접근하고 용약 정보를 빠르게 조회하며 중복 데이터의 저장을 허용하는 기능 등으로 빅데이터 기술이 확산되는 기술적 바탕이 되었다.
3세대
2007년 1월 9일 샌프란시스코 모스콘 센터에서 스티븐 잡스가 애플의 모바일 전화기를 발표했다. (2007년 = IT 빈티지 해)
4세대
2016년 3월 16일 '알파고 vs 이세돌' 9단 대결을 통해 빅데이터가 아닌 머신러닝을 통한 데이터 분석의 힘을 보여주는 압도적인 사례이다.
2. 인공지능 시대 기술
인공지능 머신러닝 딥러닝과 빅데이터
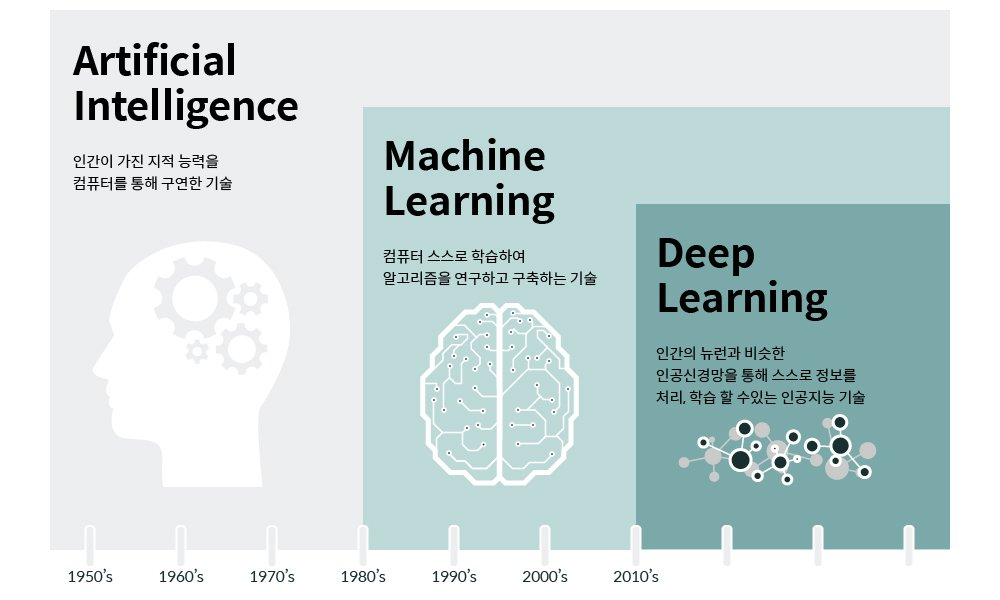
| 인공지능 | - 일반적인 사람이 수행하는 지능적인 작업을 자동화하기 위한 연구 활동 - 명시적인 규칙을 충분하게 많이 만들어 인공지능을 만드는 방법을 심볼릭 A(symbolic A)라고 하며, 1950~80년대까지 AI 분야의 지배적인 패러다임이며, 1980년대에는 전문가 시스템(export system)이 인기를 끌었음 - 심복릭 AI를 대체하기 위한 새로운 방법이 바로 머신러닝 |
| 머신러닝 | - "프로그래머가 직접 만든 규칙(rule) 대신 컴퓨터가 데이터를 보고 자동으로 규칙을 학습할 수 있을까?" 라는 질문에서 시작 - 데이터에서 통계적 구조를 찾은 뒤, 이 작업을 자동화하기 위한 규칙을 만드는 과정을 말함 - 머신러닝은 명시적으로 프로그래밍 되는 것이 아니라 훈련(training) 과정을 통해 완성됨 |
| 딥러닝 | - 딥러닝은 머신러닝에서 가장 중요한 단계인 피처 엔지니어링(feature engineering)을 자동화하기 때문에 문제 해결에 쉬움 - 피쳐 엔지니어린은 사람이 수동으로 데이터의 표현을 만드는 방법 - 딥러닝에서 자업 흐름을 단순화시켜 간단한 모델로 대체할 수 있으며, 데이터로 부터 학습하는 방법으로 성장 |
인공지능 센서가 되는 사물인터넷(IoT)
사물인터넷은 새로운 기술이 아닌 기존에 있는 기술을 응요하는 융합 신기술 분야로 데이터, 인공지능, 블록체인, 클라우드 기술 등이 융합되어 '지능형 사물인터넷' 형태로 발전하고 있다.
사물인터넷은 다른 IoT 기기들과 상호 소통하며 주변 상황 인지와 자율적 대응까지 수행하는 방향이 될 것으로 보인다.
사물인터넷 기술을 1단계 연결형(connectiveity), 2단계 지능형(intelligence), 3단계 자율형(autonomy)로 진화할 것이다.
현재는 1단계 연결형 사물인터넷을 지나 2단계를 맞이하고 있으며, 미래에는 인공지능을 통한 지능형 사물인터넷의 기회는 학습과 개인화를 동시에 촉진시킬 것이다.
인공지능 확산 핵심 인프라 클라우드
클라우드는 인공지능 구현에 필수적인 머신러닝 툴을 이용할 수 있는 플랫폼이 됐기 때문에 클라우드 컴퓨팅이 주목받고 있다.
대표적인 클라우드는 아마존웹서비스(AWS), 마이크로소프트(MS), 구글, IBM이 있다.
클라우드 업체들은 일반 개발자들도 누구나 쉽게 머신러닝 기술을 자신의 애플리케이션에 적용할 있도록 지원하고 있으며, 인공지능은 클라우드가 필요하고, 클라우드는 인공지능에서 꽃을 피울 수 있을 것이기에 향후 클라우드와 인공지능은 동반 성장이 예상된다.
인공지능 원료 빅데이터
인공지능 기술은 데이터를 실시간으로 대량 수집함으로써 엄청난 속도로 증가하고 있다.
매년 데이터 생산량은 2배로 증가하고 있고, 10년 후에는 1,500억 개의 네트워크 센서가 존재할 것으로 예측된다.
더 안전한 블록체인 기반 인공지능
빅데이터에 대한 정보들은 수집 방법 등의 세세한 정보를 공개할 의무가 없다.
하지만 블록체인 네트워크에 데이터들은 모두 사실에 기반한 것으로 이 데이터들을 활용해 보다 정확한 미래 분석이 가능해질 것이다.
예를 들어, 의료산업에서 블록체인과 인공지능은 개인의 신분 공개 없이 의료 정부 공유 시 유용할게 사용될 수 있다.
블록체인 프로토콜을 사용하여 데이터를 선택적으로 공유하게 되면 의사가 환자의 전체 병력을 병원에 상관없이 분석할 수 있게 된다.
3. 데이터 사이언티스트
빅데이터 머신러닝(이하 빅 러닝)을 위한 지식들
빅러닝은 데이터 수집과 구축, 큐레이션, 통계 분석과 머신러닝 등의 다양한 기술과 지식을 활용하여 복잡한 데이터로부터 인사이트를 얻거나 지능화된 시스템을 구현하기 위한 모든 업무를 총칭하는 개념이다.
| 분야 | 빅러닝 학습 범위 |
| 인공지능 관련 | 빅데이터란 무엇인가? |
| 머신러닝이란 무엇인가? | |
| 인공지능은 어떻게 발전했는가? | |
| 데이터 분석이란 무엇인가? | |
| 데이터 사이언스란 어떤 분야인가? | |
| 머신러닝 기술 몇 가지를 설명하시오 | |
| 통계학 기본 | 데이터 구조, 요약, 변수 |
| 샘플링, 확률 통계 기본 | |
| 범주형, 연속형 구분 | |
| 선형, 다중, 로지스틱 회귀에 대한 이해 | |
| 데이터 분석 도구(파이썬, R 등) 사용 능력 | 데이터 클린징 |
| 데이터 가져오기 및 내보내기 | |
| 데이터 조작(sorting, filtering, 변수 추출 등) | |
| 데이터 시각화 기술 | |
| EDA 이해 | 다변량, 다변량 데이터 분석 |
| 데이터 스토리 텔링 기술 | |
| 지도 학습, 비지도 학습, 준지도 학습, 강화 학습 | |
| 학습 모델 | 빅데이터 처리 기술, 빅데이터 관련 환경 |
| 빅데이터 기술 | 하둡, 스파크 하이브 등 |
| 딥러닝 기술 | ANN, NLP, CNN, tensorflow, OPEN CV |
데이터 기술자 시대
DT(Data Technology) 시대에는 데이터 기반 대중 서비스와 생산 효육성 중심으로 산업이 발전할 것이다.
그러므로 미래 시대에 경쟁은 조직이 보유하고 있는 데이터가 기업에 얼마나 많은 가치를 창출하느냐가 중요할 것이다.
데이터 사이언티스크
대부분이 석사 이상의 학위를 보유하고 있으며, 파이썬과 R등의 프로그래밍 언어는 필수이다.
SQL 데이터베이스에 대한 지식도 필요하며 비정형 데이터(소셜 미디어, 영상, 음성 등)를 다룰 수 있는 능력 또한 중요하다.
또한 통계 분석과 수학은 추론적 통계 및 실험 설계도 알아야 하며 조직 및 고객과의 의사소통 방법과 데이터 시각화 기술이 필요하다.
(모든 조건을 해당하는 사람은 전 세계 어디에도 없어요 :)
빅러닝 파이프라인

데브옵스(DevOps) 분야에도 소스 코드 작성에서 배포에 이르기까지 소프트웨어의 진행 과정을 설명하는 빌드 파이프라인이란 것이 있고, 일반 개발자에게는 코드 파이프라인이 있는 것처럼, 데이터 사이언티스트에게는 빅데이터 머신러닝 솔루션을 통한 빅러닝 파이프라인이 있다 [그림 2].